PDF-Text schnell und einfach extrahieren: So geht’s für Einsteiger

Überblick
Entdecken Sie, wie Sie schnell und einfach Text aus PDF-Dateien extrahieren – mit kostenlosen Tools und moderner OCR-Technologie. Unser Ratgeber stellt Ihnen praktische Methoden vor, mit denen Sie Zeit sparen und effizienter arbeiten. Ideal für Studierende, Berufstätige und alle, die PDF-Inhalte flexibel nutzen möchten.

Inhaltsverzeichnis


Schritte zum Kopieren und Einfügen von Text Seite für Seite


Das Kopieren von PDF-Text führt zu unleserlichen Zeichen
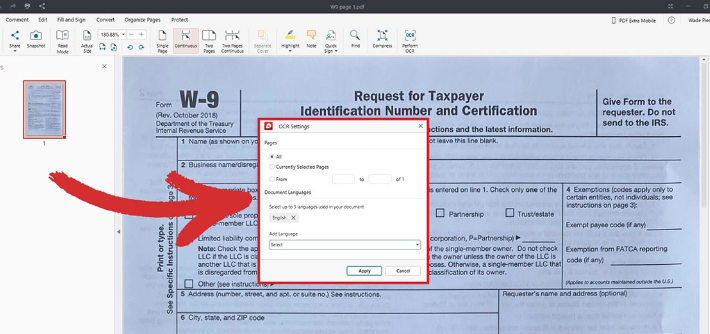
Gescannte PDF-Dateien

Einfach zu bedienen selbst ein unerfahrener Benutzer kann es im Handumdrehen tun.
Mehrere Bearbeitungsfunktionen verschlüsseln/entschlüsseln/teilen/zusammenführen/Wasserzeichen usw.
Hohe Sicherheit Der AES256 Verschlüsselungsalgorithmus wird zum Verschlüsseln und Schützen von PDF Dateien verwendet.
Schnelle Bearbeitung/Konvertierung Bearbeiten/konvertieren Sie schnell mehrere Dateien gleichzeitig.
Unterstützt die Konvertierung mehrerer Formate kann in Excel/PowerPoint/Text usw. konvertiert werden.
Einfache Bedienung auch Einsteiger können sich schnell bedienen
Mehrere Bearbeitungsfunktionen Verschlüsselung/Entschlüsselung/Aufteilung usw.
Schnelle Bearbeitung/Konvertierung Dateistapel können schnell gleichzeitig verarbeitet werden.
So verwenden Sie KI zur Textextraktion
Extract all text from this image and do not summarize the text.
Extract all text from this pdf file.

In vielen Fällen müssen Benutzer manuell Seite für Seite Screenshots erstellen, was zeitaufwändig und fehleranfällig ist. Für größere Arbeitslasten oder professionelle Nutzung bleibt dedizierte Desktop-Software die zuverlässigere und effizientere Wahl.
📊 PDF-Verarbeitung: Kostenlose vs. kostenpflichtige Tarife (Update 2025)
| Plattform | Kostenlose Version | Bezahlte / Premium-Version | PDF-Konvertierungsunterstützung | Ausgabeformate | KI-OCR-Verbesserungen 2025 |
|---|---|---|---|---|---|
Microsoft Copilot | PDFs bis zu 50 Seiten hochladen; große Dateien aufteilen. Integration mit Edge für schnelles OCR. | Microsoft 365: Unbegrenzte Seiten, KI-gestützte Tabellenextraktion. | ❌ Keine direkte Konvertierung, aber Export nach JSON über API. | Reiner Text, JSON | Cognitive Services v3.1: 98% Genauigkeit für gescannte Dokumente. |
ChatGPT (OpenAI) | Kein direkter Upload; Text einfügen oder Screenshot hochladen. | Plus/Team: Upload bis zu 300 Seiten; automatisches OCR für Bilder. | ❌ Nur Zusammenfassung; Plugins für Export verwenden. | Reiner Text, Aufzählungslisten | LlamaParse-Integration: Verarbeitet mehrsprachige PDFs (z. B. Englisch+Hindi). |
Grok (xAI) | Upload von ~50 Seiten; semantische Suche nach Text. | Premium: ~200 Seiten, Stapelverarbeitung. | ❌ Nur reiner Text. | Reiner Text | Verbessertes OCR für Scans niedriger Qualität; datenschutzorientiert. |
Was ist Renee PDF Aide?
Einfach zu bedienen selbst ein unerfahrener Benutzer kann es im Handumdrehen tun.
Mehrere Bearbeitungsfunktionen verschlüsseln/entschlüsseln/teilen/zusammenführen/Wasserzeichen usw.
Hohe Sicherheit Der AES256 Verschlüsselungsalgorithmus wird zum Verschlüsseln und Schützen von PDF Dateien verwendet.
Schnelle Bearbeitung/Konvertierung Bearbeiten/konvertieren Sie schnell mehrere Dateien gleichzeitig.
Unterstützt die Konvertierung mehrerer Formate kann in Excel/PowerPoint/Text usw. konvertiert werden.
Einfache Bedienung auch Einsteiger können sich schnell bedienen
Mehrere Bearbeitungsfunktionen Verschlüsselung/Entschlüsselung/Aufteilung usw.
Schnelle Bearbeitung/Konvertierung Dateistapel können schnell gleichzeitig verarbeitet werden.
Text nach Word extrahieren
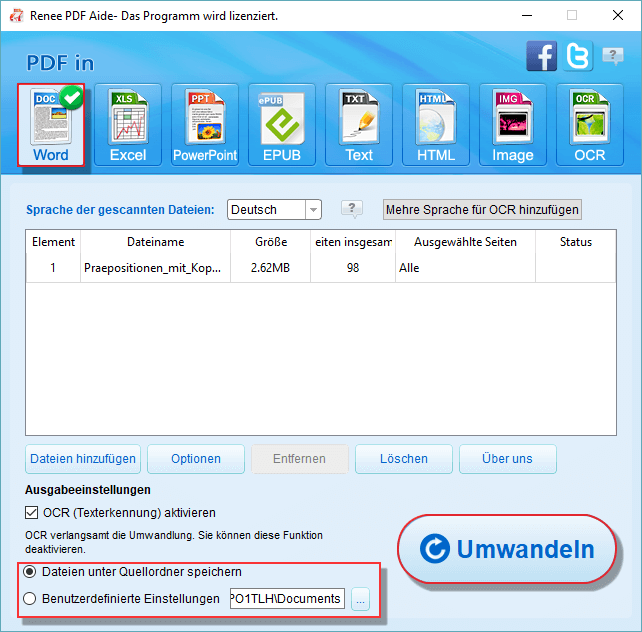
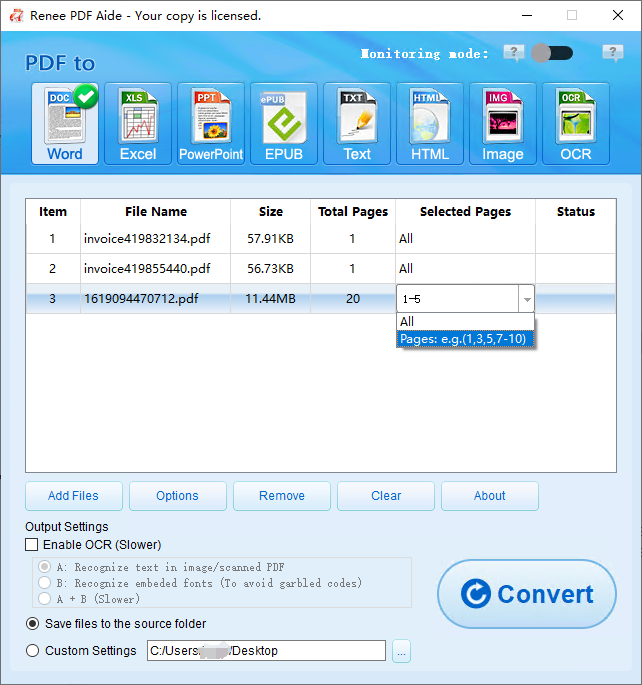

Text nach Excel extrahieren
Text nach PowerPoint extrahieren
Text nach TXT extrahieren

| Tool | Funktionen | Einschränkungen |
|---|---|---|
PDF Candy | Kostenlose PDF-zu-TXT-Konvertierung, automatisches OCR für gescannte Dateien, benutzerfreundliche Oberfläche. Ideal zum Extrahieren von Produktlisten aus Katalogen. | Dateigrößenbeschränkungen (~100 MB), Werbung in kostenloser Version, langsamer zu Spitzenzeiten, Datenschutzrisiken durch Server-Uploads. |
PDF2Go | Keine Registrierung erforderlich, unterstützt Mobilgeräte, schnelle TXT-Konvertierung mit OCR. Ideal für schnelle Notizen aus Meeting-PDFs. | Begrenzte Dateigröße, potenzielle Datenexposition, gelegentlicher Formatierungsverlust, Internet erforderlich. |
Python-Skript-Beispiel
pip install PyMuPDF tesserocr python-docx Pillow
import os
import fitz # PyMuPDF
import pytesseract
from PIL import Image
from docx import Document
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract_text_to_file(pdf_path, output_format="txt", lang="eng"):
try:
doc = fitz.open(pdf_path)
text_output = []
for page_num, page in enumerate(doc, start=1):
text = page.get_text().strip()
if text:
text_output.append(f"--- Page {page_num} ---\n{text}\n")
else:
pix = page.get_pixmap()
img = Image.frombytes("RGB", [pix.width, pix.height], pix.samples)
ocr_text = pytesseract.image_to_string(img, lang=lang)
text_output.append(f"--- Page {page_num} (OCR) ---\n{ocr_text}\n")
doc.close()
output_file = f"{os.path.splitext(pdf_path)[0]}.{output_format}"
full_text = "\n".join(text_output)
if output_format == "txt":
with open(output_file, "w", encoding="utf-8") as f:
f.write(full_text)
elif output_format == "docx":
docx = Document()
docx.add_paragraph(full_text)
docx.save(output_file)
else:
raise ValueError("Unsupported output format. Use 'txt' or 'docx'.")
return output_file
except Exception as e:
print(f"Error processing PDF: {e}")
return None
if __name__ == "__main__":
pdf_file = "sample.pdf"
result = extract_text_to_file(pdf_file, output_format="txt", lang="eng+hin")
if result:
print(f"Text extracted to: {result}")✅ Vorteile: Kostenlos, anpassbar
❌ Nachteile: Erfordert Setup
hin+eng für präzises OCR ein. Speichern Sie als TXT für reinen Text oder Word für formatierte Bearbeitung.| Benutzertyp | Beste Methode | Vorteile | Nächste Aktion |
|---|---|---|---|
Anfänger | Kopieren-Einfügen oder Online-Tools | Einfach, keine Kosten oder Kenntnisse erforderlich. | Öffnen Sie Ihre PDF noch heute in Foxit Reader. |
Professionell | Renee PDF Aide | Schnelle Konvertierungen nach Word/Excel, sicher offline. | Testversion von der offiziellen Website herunterladen. |
Technikaffin | Python mit OCR | Automatisiert, skalierbar für große Datenmengen. | Abhängigkeiten installieren und Code testen. |
Mobilnutzer | KI-Assistenten | Funktioniert überall mit Internet. | Probieren Sie ChatGPT Plus für Uploads aus. |
Was tun, wenn der extrahierte Text unleserlich oder unvollständig ist?
Sind Online-Tools für sensible PDFs sicher?
Kann ich Text aus verschlüsselten PDFs extrahieren?
Wie gehe ich mit großen PDFs um (z. B. 500+ Seiten)?
Wie extrahiere ich Text aus mehrsprachigen PDFs?
hin+eng) für präzise Extraktion aus zweisprachigen PDFs.Behält die Textextraktion die ursprüngliche PDF-Formatierung bei?
betroffene Linker :
PDF in Excel umwandeln: So übernehmen Sie Daten schnell und einfach

10-06-2025
Maaß Hoffmann : In diesem Artikel erfahren Sie, wie Sie Tabellendaten aus PDFs einfach und zuverlässig in Excel importieren. Nutzen Sie...
PDF in Google Tabellen umwandeln: So gelingt die einfache Datenübertragung

10-06-2025
Angel Doris : Erfahren Sie, wie Sie PDF-Dateien schnell und einfach mit Google Drive und Google Tabellen in Excel-Tabellen umwandeln. Der...
PDF-Text einfach in Excel übertragen: So gelingt die schnelle und problemlose Umwandlung

10-06-2025
Lena Melitta : In diesem Artikel erfahren Sie, wie Sie Text schnell und einfach aus PDFs in Excel übertragen – mit...
Gescannten PDF-Daten einfach in Excel übertragen – So klappt’s effizient
10-06-2025
Thomas Quadbeck : Erfahren Sie, wie Sie Daten aus gescannten PDFs schnell und einfach nach Excel übertragen. Entdecken Sie den Unterschied...


Benutzerkommentare
Einen Kommentar hinterlassen