PDF in DOCX umwandeln mit Python: Stapelverarbeitung, Top‑Bibliotheken & zuverlässige Tools

Überblick
Entdecken Sie die besten Wege, PDFs mit Python in DOCX umzuwandeln – von pdf2docx und PyMuPDF bis hin zu professionellen Desktop-Tools. Inklusive Stapelverarbeitung, OCR und automatischer Ordnerüberwachung für einen reibungslosen Workflow.


| Problemtyp | Typische Ursache | Vorabprüfung / Diagnose |
|---|---|---|
Gescannte PDFs | Kein auswählbarer Text | Öffnen Sie die PDF und versuchen Sie, Text zu markieren; wenn nichts markiert wird, ist OCR erforderlich |
Komplexe Tabellen/Layouts | pdf2docx hat keine Layout-Engine | Wandeln Sie zunächst eine Seite um und prüfen Sie auf verschobene Spalten |
Eingebettete Schriftarten / verstümmelter Text | Schriftuntermenge oder nicht standardmäßige Kodierung | Durchsuchen Sie das DOCX nach □ oder zufälligen Symbolen |
Abstürze bei großen Stapeln | Speicher- oder Abhängigkeitskonflikte | Testen Sie mit 5–10 Dateien; behalten Sie die RAM-Nutzung im Auge |

| Ansatz | Am besten geeignet für | Wichtigste Einschränkung |
|---|---|---|
pdf2docx | Schnelle Umwandlungen digitaler PDFs | Schwach bei komplexen Layouts; kein OCR |
PyMuPDF + python-docx | Volle Kontrolle und benutzerdefinierte Extraktionslogik | Erfordert umfangreiche Codierung für die Layout-Rekonstruktion |
pdfplumber | Tabellenzentrierte PDFs | Keine DOCX-Ausgabe; nur Textextraktion |
Pandoc | Skriptfähige Pipelines; Multiformat-Workflows | Die Qualität von PDF→DOCX hängt von LaTeX-/PDF-Lesern ab |
LibreOffice CLI | Stapelautomatisierung; Headless-Umwandlung | Layouttreue variiert; kein OCR |
| Funktion | Unterstützung |
|---|---|
Direkte PDF→DOCX | Ja |
OCR | Nein |
Eingebettete Schriftarten | Teilweise |
Komplexe Layouts | Mäßig |
Automatisierung | Ja |
XFA-Formulare | Nein |
| Funktion | Unterstützung |
|---|---|
Direkte PDF→DOCX | Nein (manuelle Codierung) |
OCR | Nein (externe OCR erforderlich) |
Eingebettete Schriftarten | Nur lesen |
Komplexe Layouts | Hohe Kontrolle, manuell |
Automatisierung | Ausgezeichnet |
XFA-Formulare | Nein |
| Funktion | Unterstützung |
|---|---|
Direkte PDF→DOCX | Nein |
OCR | Nein |
Eingebettete Schriftarten | Nein |
Komplexe Layouts | Gut für Tabellen |
Automatisierung | Ja |
XFA-Formulare | Nein |
| Funktion | Unterstützung |
|---|---|
Direkte PDF→DOCX | Ja (über LaTeX) |
OCR | Nein |
Eingebettete Schriftarten | Nein |
Komplexe Layouts | Eingeschränkt |
Automatisierung | Ausgezeichnet |
XFA-Formulare | Nein |
| Funktion | Unterstützung |
|---|---|
Direkte PDF→DOCX | Ja |
OCR | Nein |
Eingebettete Schriftarten | Teilweise |
Komplexe Layouts | Mäßig |
Automatisierung | Ausgezeichnet |
XFA-Formulare | Nein |

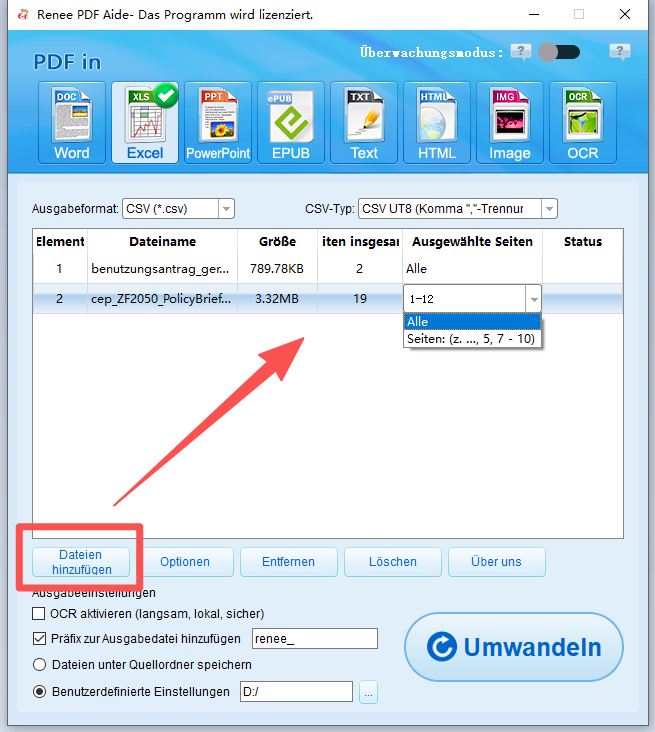
Einfach zu bedienen selbst ein unerfahrener Benutzer kann es im Handumdrehen tun.
Mehrere Bearbeitungsfunktionen verschlüsseln/entschlüsseln/teilen/zusammenführen/Wasserzeichen usw.
Hohe Sicherheit Der AES256 Verschlüsselungsalgorithmus wird zum Verschlüsseln und Schützen von PDF Dateien verwendet.
Schnelle Bearbeitung/Konvertierung Bearbeiten/konvertieren Sie schnell mehrere Dateien gleichzeitig.
Unterstützt die Konvertierung mehrerer Formate kann in Excel/PowerPoint/Text usw. konvertiert werden.
Einfache Bedienung auch Einsteiger können sich schnell bedienen
Mehrere Bearbeitungsfunktionen Verschlüsselung/Entschlüsselung/Aufteilung usw.
Schnelle Bearbeitung/Konvertierung Dateistapel können schnell gleichzeitig verarbeitet werden.
Wichtige Vorteile sind

Einfach zu bedienen selbst ein unerfahrener Benutzer kann es im Handumdrehen tun.
Mehrere Bearbeitungsfunktionen verschlüsseln/entschlüsseln/teilen/zusammenführen/Wasserzeichen usw.
Hohe Sicherheit Der AES256 Verschlüsselungsalgorithmus wird zum Verschlüsseln und Schützen von PDF Dateien verwendet.
Schnelle Bearbeitung/Konvertierung Bearbeiten/konvertieren Sie schnell mehrere Dateien gleichzeitig.
Unterstützt die Konvertierung mehrerer Formate kann in Excel/PowerPoint/Text usw. konvertiert werden.
Einfache Bedienung auch Einsteiger können sich schnell bedienen
Mehrere Bearbeitungsfunktionen Verschlüsselung/Entschlüsselung/Aufteilung usw.
Schnelle Bearbeitung/Konvertierung Dateistapel können schnell gleichzeitig verarbeitet werden.
Schritte
pip install pymupdf python-docx watchdog
import fitz # PyMuPDF
from docx import Document
from watchdog.observers import Observer
from watchdog.events import FileSystemEventHandler
import time
import os
class PDFHandler(FileSystemEventHandler):
def on_created(self, event):
if event.src_path.endswith('.pdf'):
self.convert_pdf_to_docx(event.src_path)
def convert_pdf_to_docx(self, pdf_path):
doc = fitz.open(pdf_path)
word_doc = Document()
for page in doc:
text = page.get_text()
word_doc.add_paragraph(text)
output_path = pdf_path.replace('.pdf', '.docx')
word_doc.save(output_path)
print(f"Converted: {output_path}")
if __name__ == "__main__":
path = "watch_folder" # Create this folder
if not os.path.exists(path):
os.makedirs(path)
event_handler = PDFHandler()
observer = Observer()
observer.schedule(event_handler, path, recursive=True)
observer.start()
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
observer.stop()
observer.join()
python pdf_to_docx_automate.py
Einschränkungen
- Vollständige Codekontrolle und Anpassung
- Kostenlos nutzbar für einfache native PDFs
- Einfache Integration in bestehende Python-Pipelines
Cons:
- Keine integrierte OCR für gescannte Dokumente
- Komplexe Tabellen und Bilder sind oft falsch ausgerichtet
- Erfordert externe Tools für die geplante Ausführung
- Aufwändiges Debugging für verschiedene PDF-Layouts erforderlich
| Anwendungsfall | Empfohlenes Tool |
|---|---|
Schnelltest mit 1–2 einfachen PDFs | Python-pdf2docx-Skript |
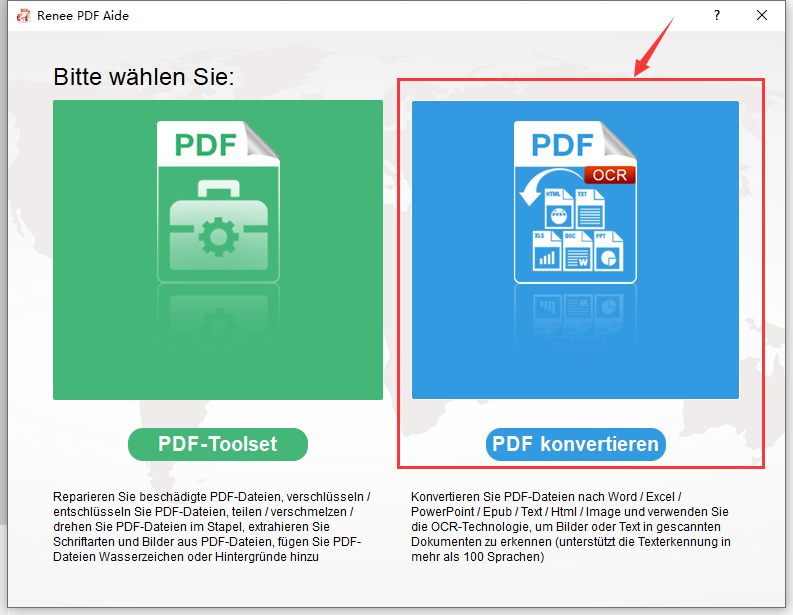
Gescannte PDFs oder komplexe Layouts | Renee PDF Aide mit OCR |
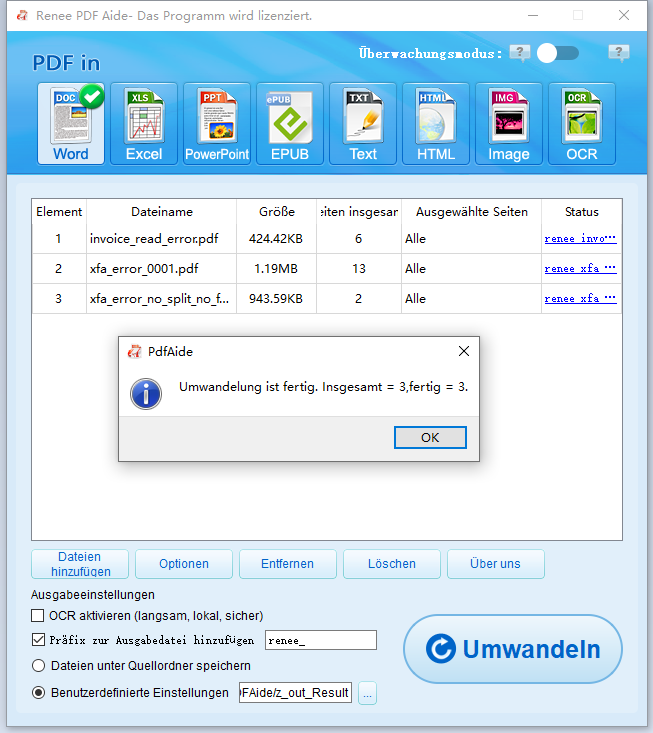
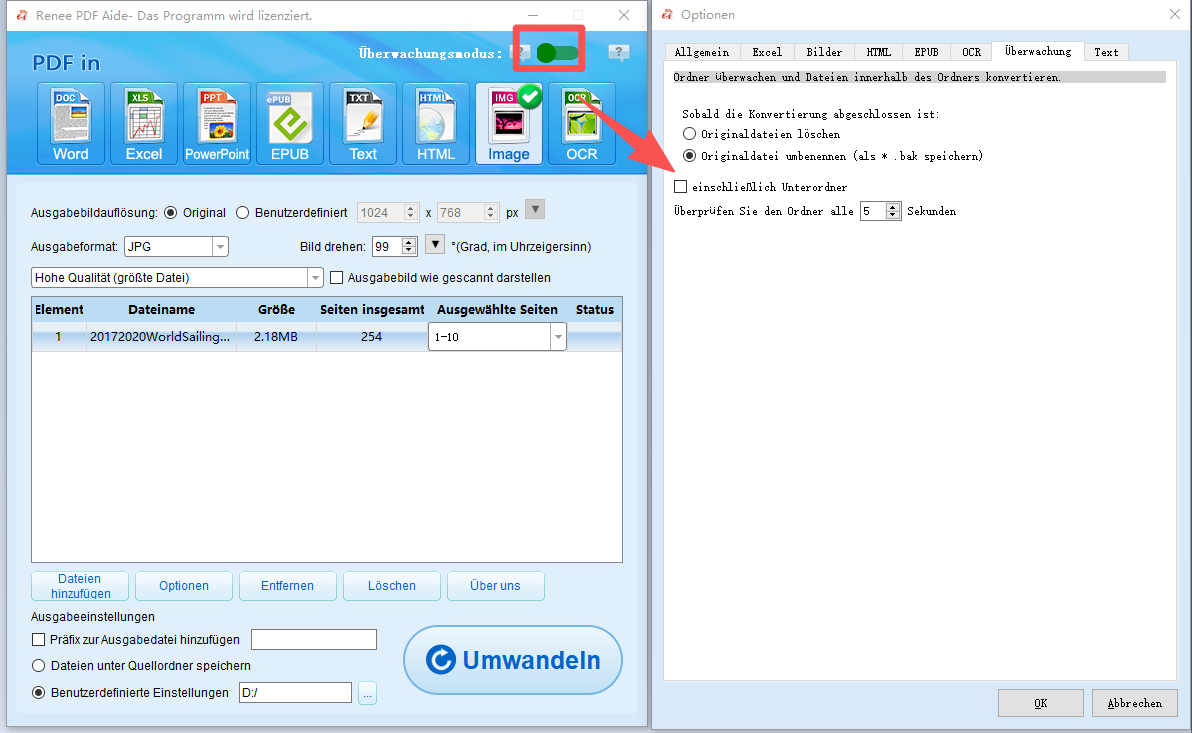
Stapelumwandlung (50+ Dateien) | Renee PDF Aide (Stapelverarbeitung + Überwachungsmodus) |
Geplante nächtliche Umwandlungen | Renee PDF Aide Überwachungsmodus |
Volle Codekontrolle + einfache PDFs | PyMuPDF + watchdog benutzerdefiniertes Skript |
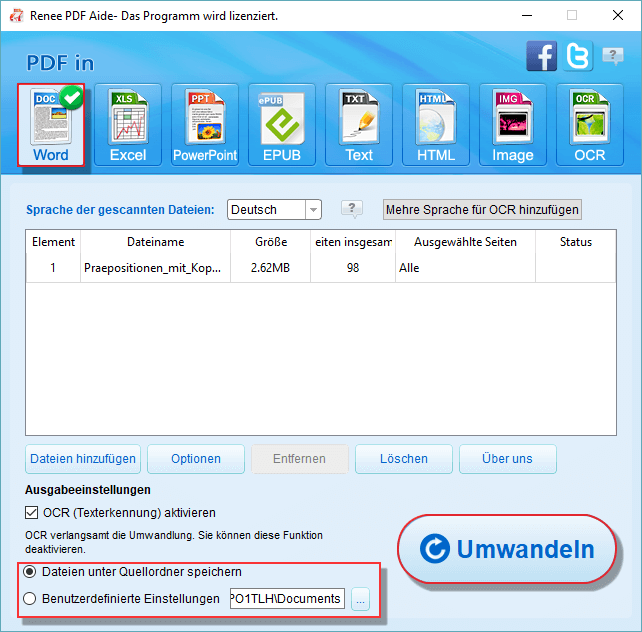
Kann Renee PDF Aide eingescannte PDFs verarbeiten, die Python-Skripte nicht lesen können?
Warum verliert pdf2docx meine Tabellenformatierung oder Spaltenausrichtung?
Welche maximale Stapelgröße oder Seitenbegrenzung gibt es in Renee PDF Aide?
Kann ich passwortgeschützte PDFs mit Python oder Renee PDF Aide in DOCX umwandeln?
Funktioniert Renee PDF Aide mit XFA-Formularen (Bank-/Behörden-PDFs)?

Einfach zu bedienen selbst ein unerfahrener Benutzer kann es im Handumdrehen tun.
Mehrere Bearbeitungsfunktionen verschlüsseln/entschlüsseln/teilen/zusammenführen/Wasserzeichen usw.
Hohe Sicherheit Der AES256 Verschlüsselungsalgorithmus wird zum Verschlüsseln und Schützen von PDF Dateien verwendet.
Schnelle Bearbeitung/Konvertierung Bearbeiten/konvertieren Sie schnell mehrere Dateien gleichzeitig.
Unterstützt die Konvertierung mehrerer Formate kann in Excel/PowerPoint/Text usw. konvertiert werden.
Einfache Bedienung auch Einsteiger können sich schnell bedienen
Mehrere Bearbeitungsfunktionen Verschlüsselung/Entschlüsselung/Aufteilung usw.
Schnelle Bearbeitung/Konvertierung Dateistapel können schnell gleichzeitig verarbeitet werden.
betroffene Linker :
PDF-Tabellen einfach extrahieren: Die besten kostenlosen & KI-Tools im Vergleich

28-10-2025
Maaß Hoffmann : Entdecken Sie die einfachsten und effektivsten Methoden, um 2025 Tabellen aus PDFs zu extrahieren – kostenlos und mit...
PDF-Text schnell und einfach extrahieren: So geht’s für Einsteiger

03-10-2025
Thomas Quadbeck : Entdecken Sie, wie Sie schnell und einfach Text aus PDF-Dateien extrahieren – mit kostenlosen Tools und moderner OCR-Technologie....


Benutzerkommentare
Einen Kommentar hinterlassen